一直不想自己搭建环境,一来是觉得有些麻烦,从ZK,Hadoop,到Spark全都得配置一遍太耽误时间,二来公司测试环境的Spark可以用则自己能省也就省了。但后来发现在Docker下部署下来可以这么轻松,于是也就自己搞了一套。简单来说docker-compose是Docker下的一个编排工具,通过使用配置文件的方式来编排,创建和管理容器,使得集群化的容器环境管理起来更加方便。这里就使用BDE Pipline Application来构建部署Spark开发环境。
1. Windows下安装Docker
1.1 安装Docker
Docker Desktop for Windows 下载地址
https://hub.docker.com/editions/community/docker-ce-desktop-windows
直接下载安装即可,因为Win OS用的是企业版,DockerToolbox的方式就不说了。
1.2 镜像加速
登录阿里云镜像地址,容器镜像服务->镜像工具->镜像加速器,获取加速器地址
https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
打开Docker的Settings窗口,左侧导航菜单选择 Docker Daemon。编辑窗口内的JSON串,填写下方加速器地址:
{
"registry-mirrors": ["https://kcw7zs40.mirror.aliyuncs.com"]
}
编辑完成后点击 Apply 保存按钮,等待Docker重启并应用配置的镜像加速器。
1.3 安装Portainer管理镜像
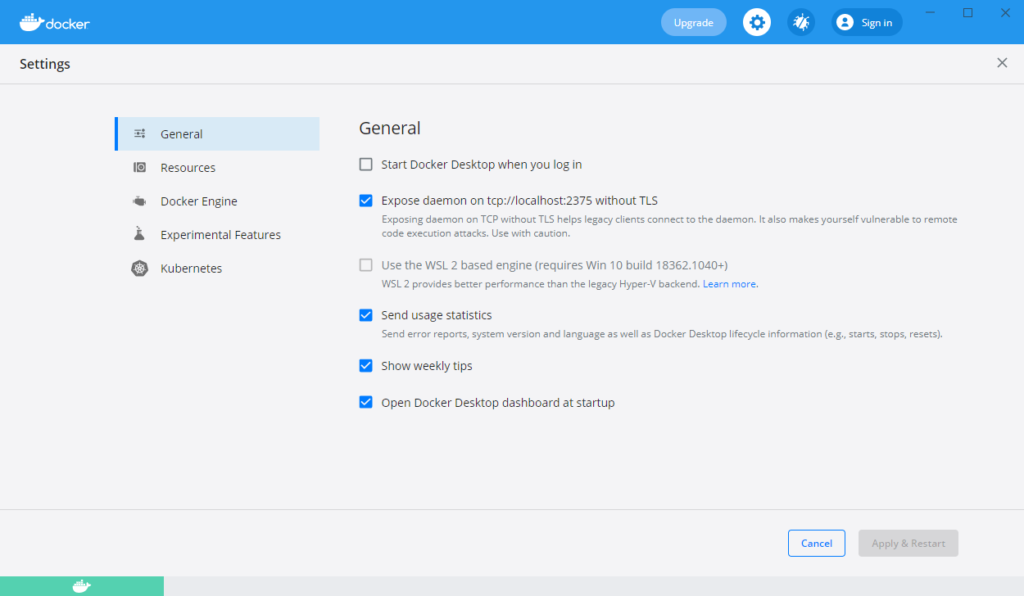
打开docker设置
勾选 Expose daemon on tcp://localhost:2375 without TLS 选项
拉取portainer镜像docker pull portainer/portainer
制作容器docker run -d --name portainer -p 10001:9000 --restart=always -v /D/docker/portainer:/var/run/docker.sock portainer/portainer
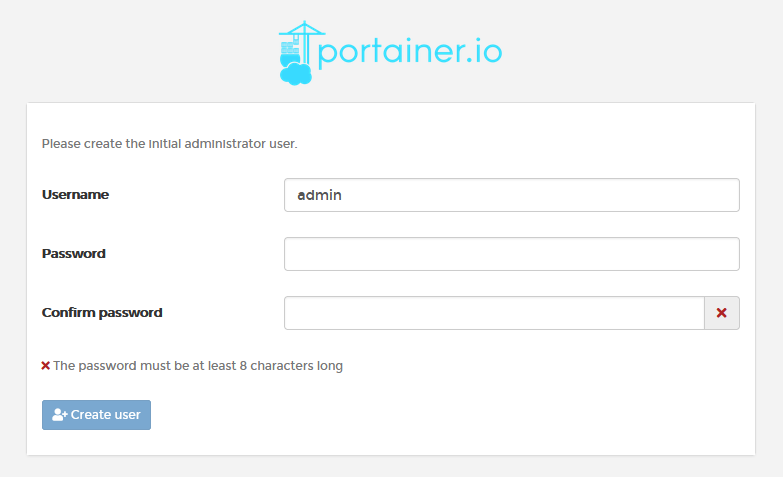
portainer初始化创建用户
浏览器打开 http://localhost:10001
设置Endpoint
Name:local
Endpoint URL:docker.for.win.localhost:2375
如果输入这里的Endpoint URL时遇到问题,链接被拒绝如下:
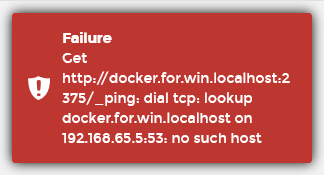
那么可以尝试用下面的
Endpoint URL:host.docker.internal:2375
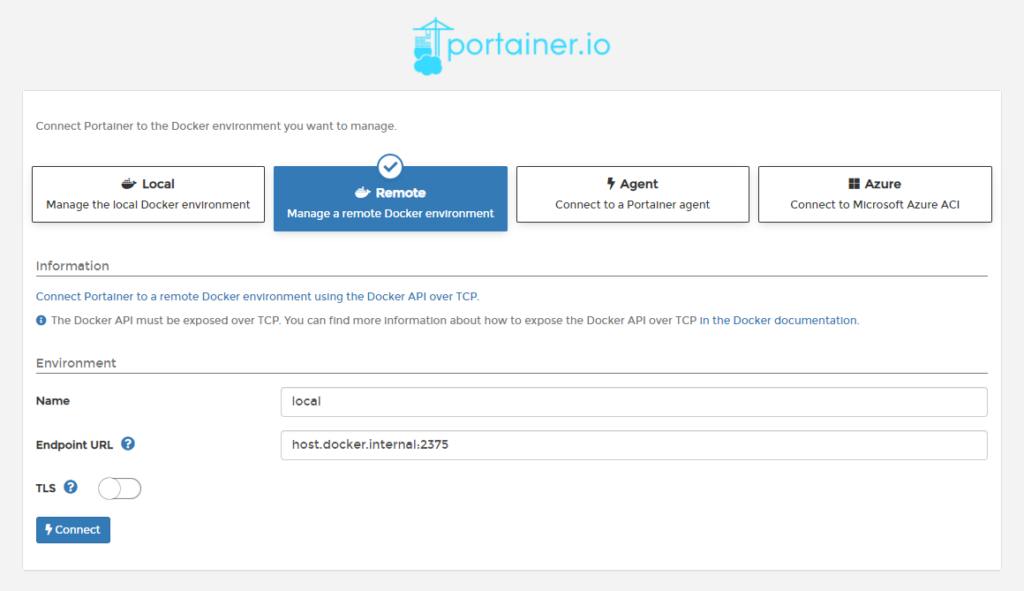
上面的问题方案来自这里:
https://stackoverflow.com/questions/63741527/docker-portainer-tcp-127-0-0-12375-connect-connection-refused
好了到这里,就已经可以通过portainer来管理我们的容器了
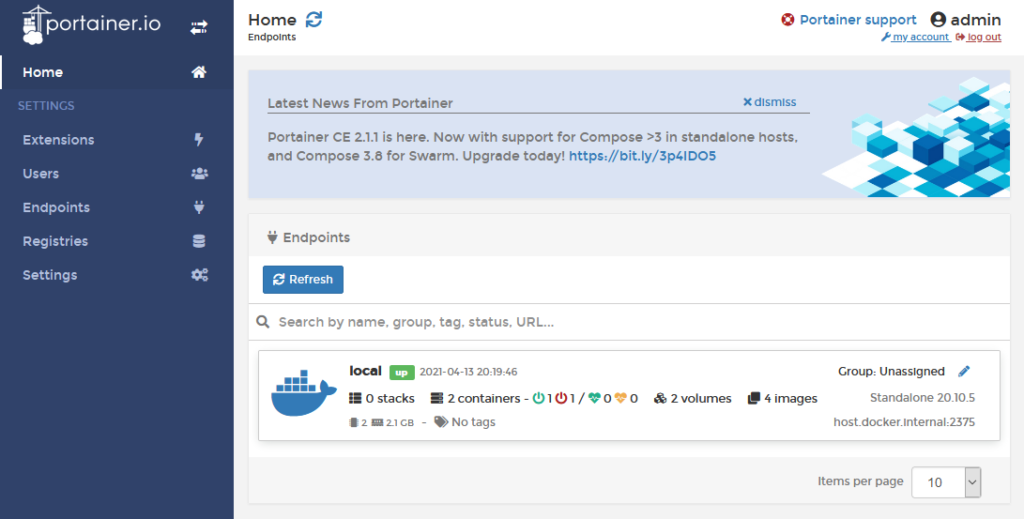
当然了,你也可以通过portainer来管理镜像加速器
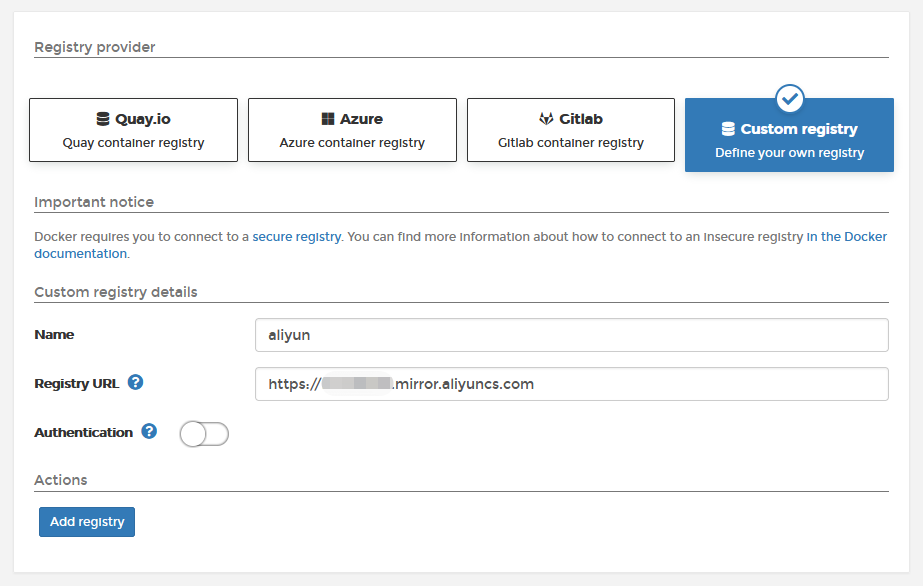
2. Windows下Docker安装Spark开发环境
2.1 安装Spark
Github地址:https://github.com/big-data-europe/docker-spark
使用BDE Pipeline application:git clone https://github.com/big-data-europe/app-bde-pipeline.git
修改docker-compose文件:
version: '2'
services:
spark-master:
image: bde2020/spark-master:3.1.1-hadoop3.2
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
environment:
- INIT_DAEMON_STEP=setup_spark
spark-worker-1:
image: bde2020/spark-worker:3.1.1-hadoop3.2
container_name: spark-worker-1
depends_on:
- spark-master
ports:
- "8081:8081"
environment:
- "SPARK_MASTER=spark://spark-master:7077"
networks:
fixed:
ipam:
driver: default
config:
- subnet: "172.20.0.0/24"
neworks.fixed.ipam.config.subnet 节点用于固定容器IP地址
构建镜像并启动容器:cd app-bde-pipelinedocker-compose up -d
-d代表后台运行
查看集群状态docker-compose ps
通过浏览器访问:
http://localhost:8080/
2.2 测试Spark
创建一个容器的伪终端docker exec -it spark-master bash
单机测试代码模式cd /spark/bin./spark-shell
提交执行示例代码./spark-submit --class org.apache.spark.examples.SparkPi --master spark://spark-master:7077 /spark/examples/jars/spark-examples_2.12-3.1.1.jar
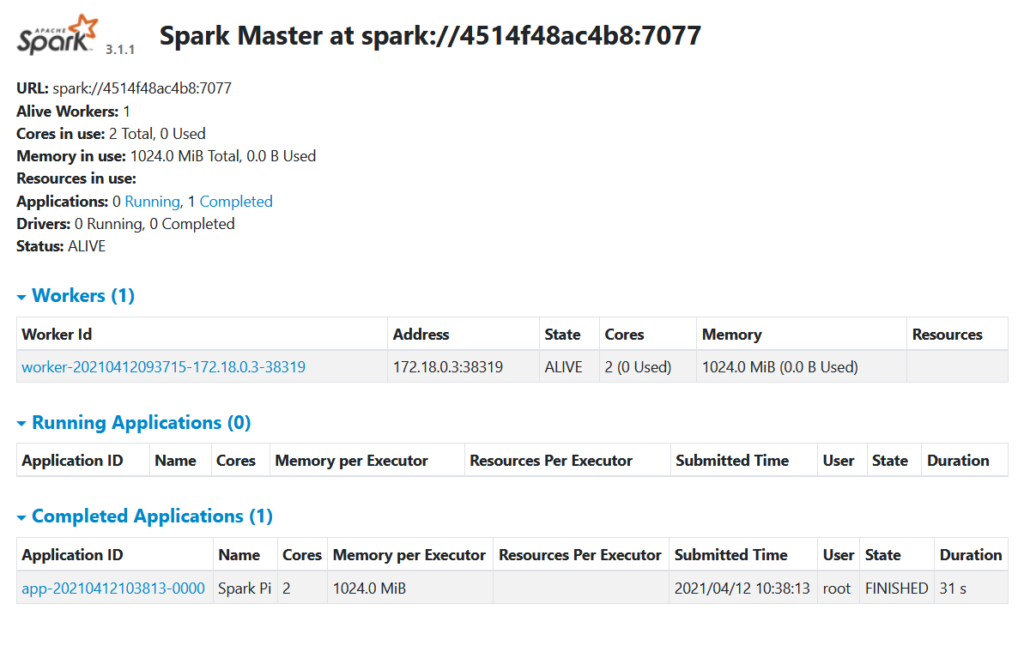
退出scala命令行:quit
退出终端exit
停止容器并移除通过docker-compose创建的容器docker-compose down
3. Windows下Docker安装Hadoop
3.1 独立安装Hadoop
安装镜像
Github地址:git clone https://github.com/big-data-europe/docker-hadoop.git
docker-compose.yml文件如下:
version: "3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
restart: always
ports:
- 9870:9870
- 9000:9000
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
restart: always
volumes:
- hadoop_datanode:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
volumes:
hadoop_namenode:
hadoop_datanode:
hadoop_historyserver:
networks:
fixed:
ipam:
driver: default
config:
- subnet: "172.20.0.0/24"
构建镜像并启动容器cd docker-hadoopdocker-compose up -d
浏览器访问:
http://localhost:9870
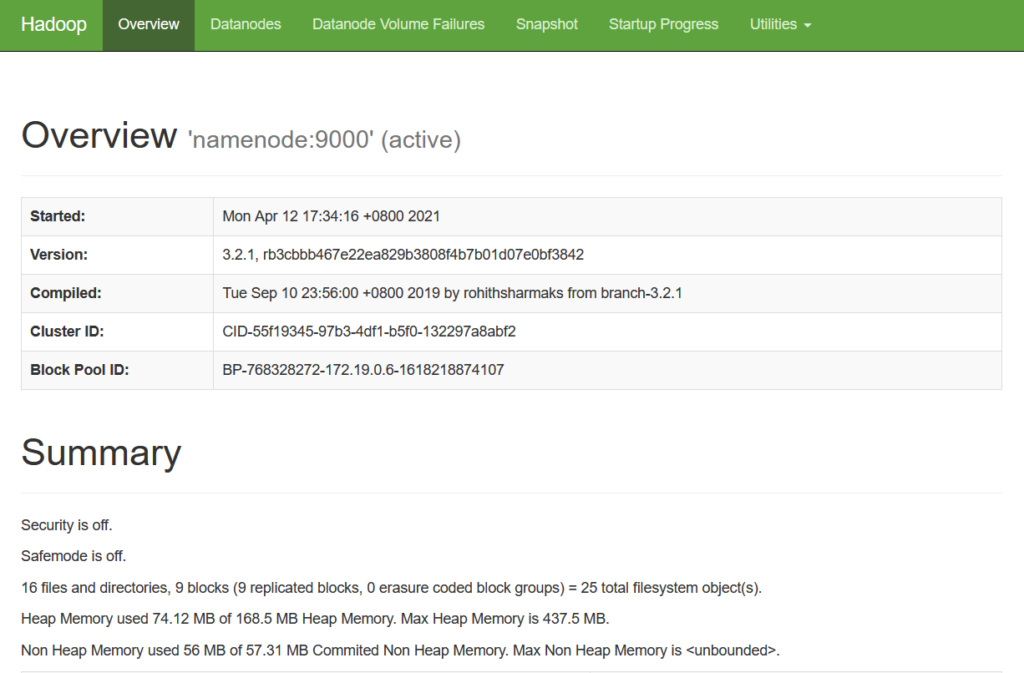
3.2 简单的测试
进入到namenode容器:docker exec -it namenode bash
在HDFS里面建一个文件夹datahadoop fs -mkdir -p data
创建目录及写入文件mkdir data; echo "Hello Docker World" > data/f1.txt; echo "Hello sundayfine" > data/f2.txt
将文件写入到HDFShdfs dfs -put ./data/* data
查看HDFS
hdfs dfs -ls -R data
删除文件hdfs dfs -rm -r data
退出终端exit
3.3 运行WordCount示例
下载WordCount示例代码:
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-mapreduce-examples/3.2.1/hadoop-mapreduce-examples-3.2.1-sources.jar
将本机jar文件复制到容器namenode里docker cp D:/examples/hadoop-mapreduce-examples-3.2.1-sources.jar namenode:hadoop-mapreduce-examples-3.2.1-sources.jar
写入hdfs文件hdfs dfs -put ./data/* input
运行WordCounthadoop jar hadoop-mapreduce-examples-3.2.1-sources.jar org.apache.hadoop.examples.WordCount input output
查看运行结果hdfs dfs -cat output/part-r-00000
删除output目录hdfs dfs -rm -r output
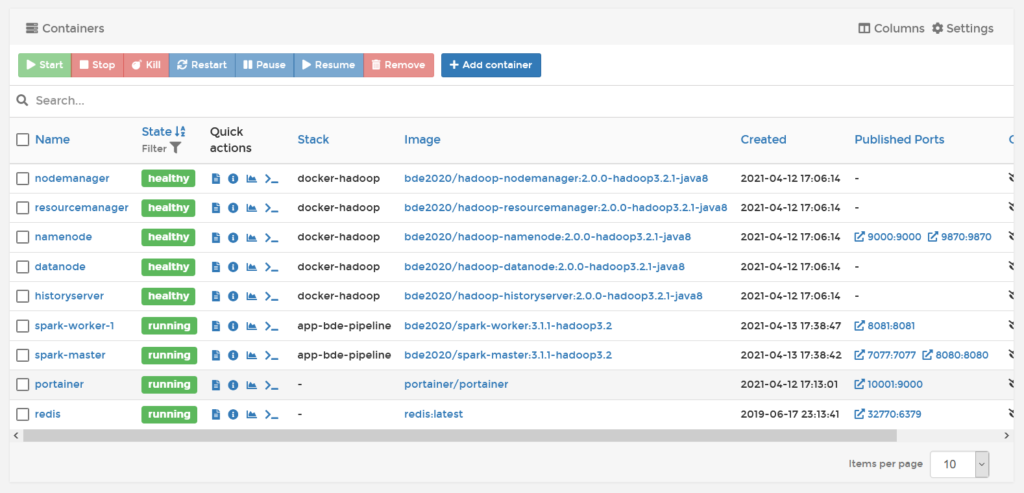
那么综上,我们Portainer中看到的所有容器就是下面这个样子