
对账系统或者对账平台,一般用于比对财务数据上的金额或者订单数据的差异等,都体现在交易的金额上。但这里说的对账平台其实并不想只局限的应用于财务,而更多的想突出一个工具,一个平台化的工具。对账的诉求起源于财务对账,并且目前已经支持多种业财间不同形式的对账工作,其次工具化的产品可以支持不同业务形态的大数据量比对。通过统一的平台建设,使得不同业务线相同或类似的对账诉求能够得以统一解决,减少人员消耗以及独立开发所造成的资源浪费。

1. 对账平台的焦点
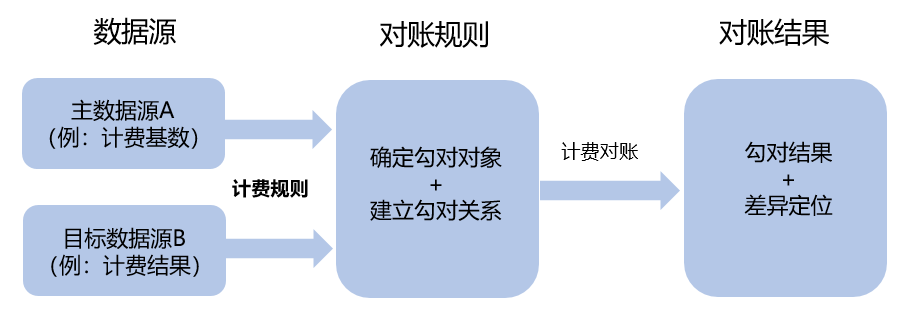
描述的简单一些,对账其实就是在两个数据源当中,找出指定范围内的相同及差异的数据。一般而言,完整的对账系统都会包含三个环节:数据的采集加工,对账,以及调账。
- 数据采集:通过将不同源的数据采集加工成标准化或易于对账的数据,为对账做准备。
- 对账:找出两个数据源中的相同及差异化的数据输出。
- 调账:针对对账差异化的金额结果,找出背后出现差异的原因,并进行财务上的调账操作。
谈到数据采集加工,以及后面调账的环节,就必然的使我们需要熟悉各个数据源的数据结构,但当我们需要对账的业务线多达几十个的时候,全部的了解所有业务侧数据结构将变得非常困难。所以当我们将对账平台的焦点聚焦在对账这个核心问题之后,我们的目的也将变得非常的清晰,就是希望为众多的业务线提供通用化的对账工具,这便要求我们能够不侵入业务逻辑,而使得平台的对账功能能够适配绝大多数的业务线,满足他们的对账要求。
因此首先我们要确定接入对账平台的一些标准:
- 提供两个数据源中已经加工好的不需要关联其他表的一张宽表数据
- 通过对账所需要的对账条件,如比对字段,比对范围,对账周期,结果输出形式等
2. 对账思路
制定好接入的标准,我们再来说说具体要怎么做对账。
需要对账的数据根据时效性一般可以分为离线数据对账,以及实时数据对账。
- 离线数据对账一般也就是数据产生之后第二天才进行对账,如T+1
- 实时对账指实时产生的数据当天就可以进行比对。
财务上一般都会采用T+1的方式对账。我们假定每天产生的业务数据量在上百万或千万级别,那么通过对账平台直连业务库将可能会对生产数据库造成压力,那么这类的情况也很适合T+1对账。这类的数据可以通过ETL的方式抽取到数仓中进行加工,分析处理。实时对账一般都采用直连业务库的方式采集数据,这就需要在对账平台配置数据源的相关信息,适用于量小的情况。
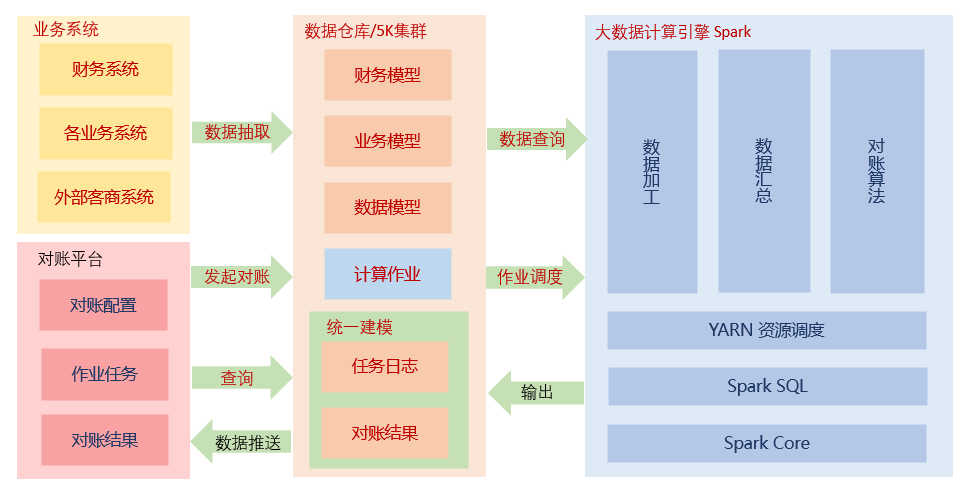
了解了两种对账场景,这里我们着重来说第一种,离线数据的对账。当离线的数据被抽取到数仓中之后,业务方可以对数仓中的数据表进行各种加工计算,最终以满足接入对账平台标准一的宽表来提供给对账平台进行对账。所以对账平台的数据采集以及加工的工作,则可以完全的交由数仓来解决。
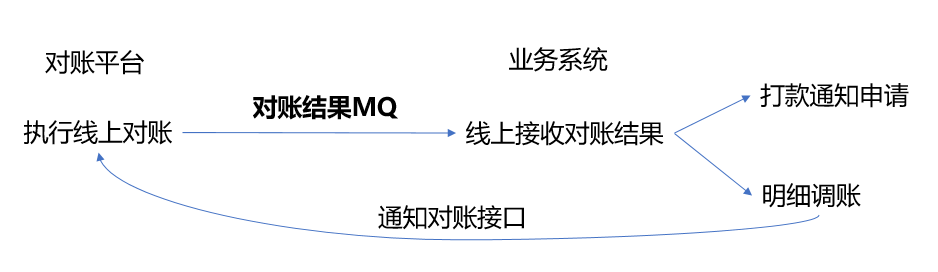
再来看调账,不同的业务线调账也是不同的,倘若调账统一在对账平台处理,那无疑加重了对账的负担,增加了和各个业务系统的耦合性。另外一个思路就是我们可以将对账结果通过接口形式开放给业务系统进行查询,而各个业务线这种个性化的调账功能则由业务系统自身来完成,这样就可以使得对账平台更加的独立,聚焦于对账本身,并将能够提供一个强大的,通用性的对账功能作为目标,进行平台化,工具化的输出,解决通用的对账类问题。
总结一下,对账平台针对上述三个不同环节采取的措施如下:
- 平台的数据采集:全部交由数据仓库处理,通过数据管道对各个业务线的业务数据进行ETL抽取,并全部存储在5K集群,可以通过计算作业对数据进行加工处理。
- 平台的对账:这里是我们关注的核心,通过通用化的设计,简洁的配置,高效率的比对,使得我们的对账环节能够解决大多数业务线的通用的数据对账问题,后面详细说明。
- 平台的调账:开放对账结果查询接口,业务系统自主的进行调账或者差异处理需求的开发。
3. 对账需求拆解
3.1 对账数据间的关系
我将需要比对的两个数据源称为主数据源与目标数据源,那么通常比对的两个大数据源的数据关系会有如下的三种情况:
- 一对一:主数据源与目标数据源表之间的数据是一对一的关系,即通过一个或多个字段的组合最多在另一张表中找到一条相应的记录
- 一对多:数据表中的记录是一对多的关系,即主表的记录可以在目标表中找到相应的多条记录,场景如订单表与订单明细之间的关系。
- 多对多:主数据源表中的多条记录与目标表中的多条记录进行比对,如业务系统中的订单明细与财务系统中的结算明细数据进行比对
当然,在不影响业务含义的情况下,针对不同的对账数据间的关系,其实都可以转化成一对一的关系进行比对。如一对多以及多对多的关系,我们都可以将数据分组汇总后,通过一对一关系进行匹配比对。
3.2 对账的维度
在业务的对账需求上,数据会存在下面两种情况的对账:
- 明细对账:要求最细粒度的对账,具体到表中的每一条记录进行比对。
- 汇总对账:只要求按照需要的维度汇总后比对总金额,总数量等汇总后的数据。
汇总对账的维度可能不只一个。例如,业务上可以按照商家和月度进行汇总后对账。也可以按照,商家及产品维度汇总后进行对账,总之汇总对账的维度其实是灵活多变的,应当可以完全按照不同的业务线进行配置。
3.3 对账数据的范围及周期
对账的周期可以说应该是相对比较自由的,不同的业务线可以按照自己的结算周期进行对账,因此常见的对账周期有:
- 按天对账:每天对前一天的数据
- 按周对账:每周一对上一周的数据
- 按半月对账(类似 1号-15号,15号-月末):每月初或月末对向前推半个月的数据
- 按自然月对账(或形如 上月28号-本月27号这样):每个月的几号对上一个月的数据
- 按照季度对账:每个季度的开始对上一个季度的数据
- 可以扩展的其他的对账范围
在这里我们要求对账平台中,对账的周期与对账的范围是需要完全可以根据不同的业务需要进行不同的配置的。
3.4 对账触发条件
对业务来说,并不会管你要怎么实现对账,他们只会关心不要让我太累,并且当我想受累时要重新对下历史的账单的时候,你还要能给我支持,所以你必须什么都能干。好吧,那么我们的对账任务什么时候触发?
- 自动对账:定时进行对账
- 手动触发:由人工手动来触发进行对账
对,就是要这么任性,原本是按天对账的任务,我就是要对10天以前的数据,来给我重跑下。所以在需求当中,这个设置也要考虑进来。
3.5 对账结果的输出
对账结果包含了两部分,第一是交集,也就是相同的数据,第二部分是差集,也就是不同的部分,即有差异的部分。在很多的对账诉求当中,有的业务线需要输出全量的数据,即包含交集和所有差集,而有的业务线则只需要保留有差异的部分即可。因此根据不同的对账诉求,我们将对账结果输出模式设置成如下四种:
- 全量存储:存储主数据源全量以及主/目标源之间全部差异数据
- 全量差异存储:仅存储两个源之间所有差异数据
- 主数据源差异存储:仅存储主与目标源不一致以及不存在于目标源的数据
- 目标数据源差异存储:仅存储不存在于主数据源以及与主不一致的目标源数据
4. 整体的对账流程
当我们有一个对账需求进来时,我们希望整体的对账是下面这样:
- 接入数据源:即用户告诉对账系统,你要对账的两个数据源表在哪里,归属哪个业务线。
- 配置对账作业:新增一项对账作业,在其中,配置对账所需要的上述所有参数。
- 作业调度:定时任务检查每一个对账作业,判断是否是当天需要对账,如果是则会生成一个对账任务。
- 任务调度:针对上一步生成的对账任务,分批将对账所需要的参数,向Spark提交任务进行对账并输出结果。
5. 对账规则的配置
想要做到通用化的对账平台,就要对所有可能的对账逻辑进行拆解,其实仔细想想,对账的逻辑无非就是查出数据进行比对,类似于我们写的SQL。那么我们就先来考虑数据查询的部分,将对账的数据查询拆解成如下几个部分:
- 查询字段:主数据源与目标数据源的查询字段,针对含义相同的字段可以设置相同的别名。
- 对比字段:在查询出来的字段中,我们需要对比那些字段。
- 主键字段:用于处理两个数据源记录之间的映射关系,如,一对一的情况,我们通过业务主键进行关联,如订单编号等
- 数据源:这里我们需要指定两个比对的数据源来自哪个库表
- 查询范围:两个数据源都有一个自己的Where条件,同时我们也会在条件上带一个查询的日期范围
- 汇总条件:如果是汇总对账,则需要填写相应的汇总字段
- 输出字段:对于对账结果的输出,我们最终会持久化到数仓或关系型数据库当中,因此需要最后输出的字段还是区别于查询字段的。
- 输出表:对账结果输出的字段存放在哪个库的哪张表中。
通过上面的分析,其实我们已经将两个数据源的查询与比对进行了拆解和剥离,将原本涉及到业务含义的过滤条件,完全交给用户来配置,系统只需要根据对账的配置条件,组装出我们需要的查询数据进行对账即可。
那么结合上面的拆解,再来考虑我们整体对账配置的设计。
- 数据源表:存储所有的数据源表信息,区分对账的数据源表以及对账结果输出表。
- 对账作业表:指定需要对账的两个数据源,对账区间,对账时间,存储位置,存储配置,状态等字段。
- 对账规则表:定义对账规则,分为明细对账还是汇总对账。
- 对账规则字段映射表:上面我们的四类字段都可以存入到这张映射表中,通过分类区分:1.查询列,2.对比列,3.匹配列,4.存储列。
- 对账规则扩展表:用于存储对账规则中两个数据源的过滤条件以及汇总条件。
- 对账任务表:对账作业根据对账时间定时生成每一天的对账任务用于具体的对账,并记录对账任务的执行情况。
6. 对账实现方案
前面说了对账平台主要关注的点以及在业务上的对账诉求之后,我们再来聊聊对账的具体实现方案。
- 应用程序/SQL比对:针对不同的业务线,编写不同代码段或不同的SQL进行比对,当遇到大数据量的记录时,比对效率较低,需要编写不同的脚本来执行对账,工作量较大,并且不通用。
- Redis的Set集合比对:需要将比对的数据存放到Set集合,再求交集与差集。对于简单对账诉求以及简单的数据结构容易比对,但涉及到数据的加工则存在一些局限。
- Spark/SparkSQL比对:使用大数据计算框架进行大数据的处理,量大情况下效率比较高,且内置函数对复杂数据结构进行加工也较为容易。
这里主要使用Spark来进行对账处理,我们通过将参数进行拆解,并直接查询数仓中的业务数据进行比对,可以使我们更聚焦于对账的算法设计,以及可视化的参数配置。
6.1 为什么是Spark?
为什么选择Spark来做对账其实有下面几个原因:
- 大数据量:高峰时,我们的对账数据量将达到上千万甚至上亿的数据,在大数据量的处理方面使用大数据计算框架将大大提高运行效率。
- 多业务线:由于需要支持的业务线众多,涉及的数据源也相应较多,对账系统无法详细的了解每一个业务线的数据结构,因此我们将数据的抽取交由数仓来解决,将数据源的接入开放给用户。需要对账的业务首先将数据抽取到数仓,通过数仓的加工,使得数据能够标准化,避免表间的关联关系渗入业务逻辑的处理,而影响对账。Spark可以直接查询数仓中的数据,简单高效。
- 内置函数:在SparkSQL中内置的函数可以方便的使得在对账过程中对查询参数进行加工处理。如regexp_extract等
当然这也有一些局限,比如无法实时对账,目前我们的数仓实时抽数还没开放,因此实时对账无法通过数仓进行采集,只能通过直连的方式,但我们核心的对账算法是不变的。但即使不是数仓,比对数据源来自独立的Mysql,其实也一样的,核心的算法是不变的。总之相较于其他的方案,Spark是最理想的选择。
差不多先到这里吧,本文详细聊了对账平台解决的核心问题,对账需求的分析,以及技术的选型,剩下的下一篇再继续分享。
感谢博主期待更新下一篇
感谢博主分享,期待下一篇